

Un utilisateur qui recherche un produit sur Internet, s'attend à trouver au minimum une image et quelques phrases qui le décrivent. Ces éléments sont en général rassemblés dans une fiche produit qui contient aussi des propriétés structurées sous la forme de noms et de valeurs avec des types prédéfinis. Par exemple s'il s'agit d'un téléphone, la fiche produit indiquera la taille de l'écran en pouces, sa capacité en gigaoctets, le système d'exploitation (iOS, Android, …). Ces attributs structurés sont des informations élémentaires dont il existe une description (métadonnées) permettant de comprendre ce qu'elles représentent et comment les exploiter automatiquement, alors que les images et les textes qui sont des données non-structurées, contiennent de l'information plus difficilement accessible par les algorithmes classiques.
Les données structurées permettent à un utilisateur de filtrer ses résultats de recherche, en sélectionnant des valeurs d'attributs qui l'intéressent : sur un site de E-Commerce, il pourra envoyer à un moteur de recherche, la requête « téléphone », puis ne faire apparaître que certains modèles, certaines capacités mémoire ou tailles d'écrans parmi les valeurs qui lui sont proposées. A l'inverse, un produit dont on ne possède qu'une image et une description ressortira diffi- cilement des résultats de recherche parce qu'il ne pourra pas être regroupé avec des produits similaires, de la même catégorie ou ayant les mêmes attributs. Sa visibilité à travers les moteurs de recherche sur Internet (Search Engine Optimization) sera faible. L'expérience utilisateur et le trafic d'un site web commercial dépendent pour une part importante, de la qualité du catalogue de produits, de l'exactitude de leurs catégories et de leurs attributs.
Pour obtenir des données structurées, on peut utiliser des référentiels, qui sont des bases de données de produits avec des numéros de référence uniques et des attributs renseignés. Certains référentiels sont construits par les fabricants des produits eux-mêmes, d'autres par des plateformes E-Commerce ou par des acteurs spécialisés dans la construction de bases de données de produits. Il suffit ensuite de relier les produits qu'on veut mettre en vente à ces référentiels. Mais certains produits n'existent dans aucun référentiels, comme lorsqu'il s'agit de vêtements de fabricants inconnus et même quand ils existent, la correspondance est parfois difficile à établir parce qu'on ne dispose pas de numéro de référence correct. Un enjeu majeur pour les plateformes d'ECommerce est donc de transformer les données non-structurées en données structurées. C'est ce qui est possible avec différentes techniques de machine learning, en particulier avec les réseaux de neurones et le deep learning.
Les messages envoyés par les clients, constituent un autre exemple de données non structurées. Il est souvent nécessaire de passer par des formulaires de contact pour envoyer un message au service client, ce qui force l'utilisateur à préciser le type de sa requête et à donner certaines informations dans un format prédé fini et génère des données structurées. Mais c'est une contrainte difficile à imposer aux utilisateurs, qui ne sélectionnent pas toujours l'option décrivant le mieux leur problème et inscrivent l'essentiel des informations dans le corps du message. Là encore, les techniques récentes de machine learning sont très utiles pour transformer ce contenu en données structurées.
Le texte et les images sont faciles à interpréter
pour la plupart des humains et ils
étaient difficiles à traiter automatiquement
par les ordinateurs jusque récemment.
Une image digitale est constituée
de quelques milliers de pixels en largeur
et en hauteur, ce qui correspond pour la
totalité d'une image à des millions de
pixels dont chacun contient des valeurs
de luminosité et de couleurs. Chacune
de ces millions de valeurs peut être représentée
suivant un axe ou une « dimension
» et donc l'image complète peut
être représentée mathématiquement
comme un point, plus exactement un
« vecteur », dans un espace qui n'est pas
l'espace à trois dimensions auquel nous
sommes habitués mais un espace de millions
de dimensions.
 Quant aux textes,
ils sont constitués de mots qui peuvent
être répertoriés dans des dictionnaires
(éventuellement spécifiques au domaine
d'application). Le moyen le plus simple
de les transformer en vecteurs numériques
est de considérer un espace composé
d'autant de dimensions qu'il y a de
mots dans le dictionnaire et suivant
chaque dimension d'indiquer par 0 ou 1
si le mot est présent. On se retrouve
comme dans le cas des images avec un espace
de très grandes dimensions.
Quant aux textes,
ils sont constitués de mots qui peuvent
être répertoriés dans des dictionnaires
(éventuellement spécifiques au domaine
d'application). Le moyen le plus simple
de les transformer en vecteurs numériques
est de considérer un espace composé
d'autant de dimensions qu'il y a de
mots dans le dictionnaire et suivant
chaque dimension d'indiquer par 0 ou 1
si le mot est présent. On se retrouve
comme dans le cas des images avec un espace
de très grandes dimensions.
On aimerait traiter les images et les textes de la même manière que des données plus simples qu'on peut regrouper par similarité ou comparer pour établir si elles correspondent à un même produit. Pour cela, il est indispensable de les représenter dans des espaces de dimensions plus raisonnables dans lequel les distances peuvent être interprétées en termes de proximité sémantique, c'est-à-dire que la distance mesurée entre les représentations des produits permettra d'établir leur degré de similarité. Si on traite un attribut simple comme la diagonale d'un écran, qu'on peut représenter suivant une seule dimension, il est facile d'en comparer les valeurs pour différents produits ou de regrouper les produits ayant des tailles d'écran similaires. L'espace dans lequel nous cherchons à représenter les textes et les images doit avoir des propriétés qui nous permettent de faire des comparaisons et regroupements de la même manière, ce qui est impossible si on se place par exemple au niveau des pixels: si pour comparer deux images, on compare les valeurs de chacun de leurs pixels, on pourra seulement établir que les images sont strictement identiques mais dès qu'il existera la moindre variation de luminosité ou de position d'un objet qu'elles représentent, il sera impossible d'évaluer leur similarité.
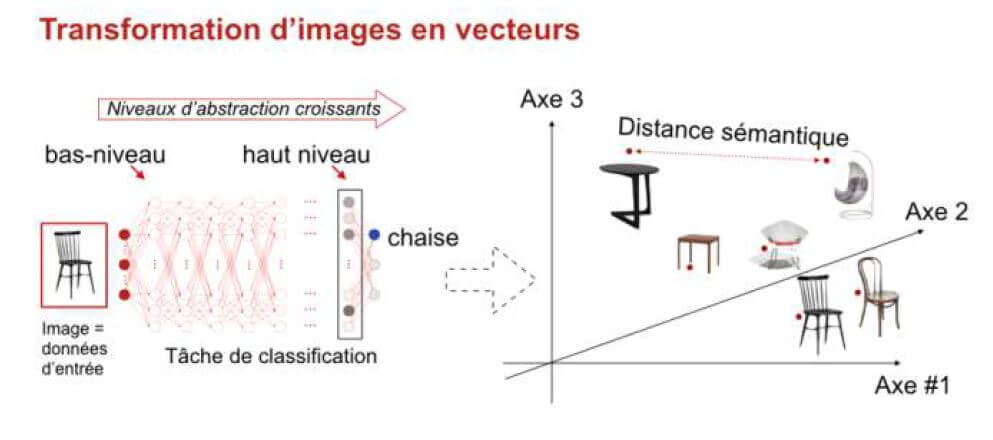
Pour transformer les images en données mieux exploitables, on peut utiliser des réseaux de neurones artificiels, qui sont inspirés du cerveau et qui se présentent sous la forme de couches de cellules élémentaires interconnectés. Ces réseaux ont une couche d'entrée dans laquelle on copie les données brutes de plus bas niveau comme les pixels d'une image et une couche de sortie dans laquelle on obtiendra des informations de plus haut niveau comme la catégorie d'un produit ou certains de ses attributs (couleur, forme, matière, …). Durant une phase d'apprentissage, les réseaux sont entraînés en utilisant une base d'exemples constituée d'images et d'attributs qui leur sont associés durant ce qu'on appelle « l'annotation » par des humains. Comme l'apprentissage est guidé par ces annotations, on l'appelle apprentissage supervisé (il existe aussi en machine learning des apprentissage auto-supervisés et non-supervisés). Grâce à l'apprentissage, les réseaux de neurones deviennent capables de prédire des attributs structurés, à partir d'une image provenant de l'ensemble d'apprentissage mais aussi par généralisation, à partir d'images inconnues qui se situent dans le même domaine d'application, comme des images de vêtements s'il s'agit de commerce en ligne et qu'on veut prédire par exemple leur couleur ou leur matière.
Lorsqu'il y a de nombreuses couches de neurones intermédiaires entre l'entrée et la sortie, cette technique de machine learning est appelée deep learning, le terme désignant une grande profondeur dans la succession des couches de neurones (et non une compréhension profonde du problème). Plus une couche de neurone est proche de la sortie, plus les informations qu'elle contient sont d'un haut niveau d'abstraction. C'est une propriété de ces réseaux de neurones d'apprendre à transformer des données de très bas niveaux en concepts de plus en plus abstraits, à travers l'extraction de caractéristiques de plus en plus haut niveau. Ainsi les images fournies en entrée sont composées de millions de pixels qui pourraient représenter n'importe quoi et même ne rien représenter d'autre que des signaux aléatoires. Mais lorsqu'on s'intéresse à un domaine particulier comme les images représentant une catégorie de produits, le réseau découvre progressivement grâce à l'algorithme d'apprentissage, des régularités qui caractérisent le domaine et en extrait dans les couches intermédiaires des représentations permettant d'en distinguer des sous-catégories et d'en extraire des caractéristiques.
En plus des résultats produits en sortie des réseaux de neurones il est donc possible d'exploiter les données des couches intermédiaires. On peut utiliser les valeurs des neurones d'une couche proche de la sortie et contenant moins de neurones qu'en entrée, comme une représentation de très haut niveau de l'image traitée. Il est difficile de déterminer à quoi correspond cette représentation numérique mais on peut supposer qu'elle correspond à des caractéristiques visuelles utiles pour décider de la catégorie d'objet qui se trouve dans l'image, comme des informations de forme et de couleurs. Si on veut distinguer des images de chats et de chiens, on peut considérer qu'une tête ronde et des oreilles pointues seront plutôt celles d'un chat mais il est impossible de répertorier la totalité des critères utiles pour distinguer sans erreurs les deux espèces d'animaux. La phase d'apprentissage automatique des réseaux de neurones ajuste des paramètres de transformations successives de l'image à travers le réseau, produisant ainsi des caractéristiques appropriées pour distinguer différentes classes d'objets. Ce ne sont pas des critères explicites comme nous pourrions les imaginer tels que les oreilles pointues des chats, mais des ensembles de paramètres numériques qui ont un usage analogue.

D'autres techniques à base de réseaux de neurones sont utilisées pour le traitement des textes en langage naturel et créent une représentation numérique d'un mot, d'une phrase ou d'un texte, avec un haut niveau d'abstraction. L'idée est de représenter les mots en fonction de leur usage ou du contexte dans lequel ils apparaissent. De la même manière que des réseaux de neurones s'appuient sur les régularités statistiques des images dans un domaine particulier, comme les images d'animaux ou les images de vêtements, pour en extraire des représentations de haut niveau, ils peuvent s'appuyer sur des régularités du langage pour créer une représentation mathématique très intéressante des mots. L'une des premières techniques de ce type, word2vec, est apparue dans les années 2010, à la même période que le deep learning. Dans le cas des images comme du texte, les données d'entrée sont complexes et leur représentation numérique directe est de très grande dimensionnalité. Le nombre de mots dans un dictionnaire ou le nombre de pixels d'une image, conduit à les représenter dans des espaces ayant des centaines de milliers de dimensions au lieu des trois dimensions de l'espace qui nous est familier. Word2vec et des techniques similaires qui lui ont succédé, permettent de visualiser des mots ou des portions de texte sous forme de vecteurs, en les regroupant suivant leur signification, en fonction des concepts auxquels ils se rapportent. La distance entre les vecteurs associés aux mots est alors une distance sémantique qui indique dans quelle mesure ils se rapportent à un même attribut ou correspondant à la même catégorie d'objet, si on parle de produits. On a donc des méthodes qui permettent de traiter les descriptions et les images de produits comme des données beaucoup plus simples. Ces représentations numériques d'images ou de mots sont appelées en anglais embeddings.
Les images et les textes deviennent facilement exploitables, avec les réseaux de neurones et le deep learning, ce qui améliore la qualité des catalogues de produits sur Internet, mais aussi le traitement des messages qui arrivent aux services clients. Au-delà du E-Commerce, les réseaux sociaux et de nombreux autres services sur Internet font beaucoup appel à ces techniques pour personnaliser le contenu envoyé à chaque utilisateur. Les images et les messages n'ont plus de secrets et deviennent des données utilisables comme les autres.




























